Gebruik CBS Open Data in R
Inleiding
In deze post een eenvoudig voorbeeld hoe je makkelijk open data van het CBS kunt downloaden m.b.v. cbsodataR om er daarna een analyse op te doen in R, bv om een tree te bouwen m.b.v. recursive partitioning (party)
De CBS data API
library(tidyverse)
library(cbsodataR)
library(party)
library(knitr)Om informatie over alle datasets te krijgen kun je ‘cbs_get_datasets’ gebruiken
ds <- cbs_get_datasets("Language" = "en")
print(paste(nrow(ds), "datasets"))## [1] "844 datasets"Dan krijg je 844 records met de volgende informatie per dataset:
names(ds)## [1] "Updated" "Identifier" "Title"
## [4] "ShortTitle" "ShortDescription" "Summary"
## [7] "Modified" "MetaDataModified" "ReasonDelivery"
## [10] "ExplanatoryText" "OutputStatus" "Source"
## [13] "Language" "Catalog" "Frequency"
## [16] "Period" "SummaryAndLinks" "ApiUrl"
## [19] "FeedUrl" "DefaultPresentation" "DefaultSelection"
## [22] "GraphTypes" "RecordCount" "ColumnCount"
## [25] "SearchPriority"Kerncijfers Buurten en Wijken
Ook kun je via de API zoeken in de beschrijvingen van de datasets en ben voor nu geinteresseerd in de Kerncijfers wijken en buurten. De resultaten zijn gesorteerd op basis van een query score, de eerste 5 zijn:
res <- cbs_search(c("Kerncijfers,wijken,buurten"),
language="nl",
format="raw",
verbose = FALSE)
kable(res$response$docs %>% select(1:2) %>% head(5))| PublicationKey | PublicationTitle |
|---|---|
| 84799NED | Kerncijfers wijken en buurten 2020 |
| 84583NED | Kerncijfers wijken en buurten 2019 |
| 84286NED | Kerncijfers wijken en buurten 2018 |
| 83765NED | Kerncijfers wijken en buurten 2017 |
| 83487NED | Kerncijfers wijken en buurten 2016 |
Na download lijkt de dataset van 2020 op moment van schrijven niet compleet vandaar verder met de versie van 2019 met ID 84583NED
metadata <- cbs_get_meta("84583NED")Dat zijn 157 variabelen, in deze post gebruik ik een beperkt aantal variabelen op gemeenteniveau gerelateerd aan stedelijkheid en type bedrijven in de gemeente. We halen wel de hele dataset op en filteren dan lokaal om optimale controle te hebben. Het is ook mogelijk via de API te filteren, maar dat geeft soms onverwachte resultaten omdat er bijvoorbeeld extra spaties achter een waarde staan.
data_all <- cbs_get_data("84583NED")Van de opgehaalde data wil ik met de volgende variabelen verder werken.
mycols <- c("Gemeentenaam_1",
"MateVanStedelijkheid_115",
"BedrijfsvestigingenTotaal_91",
"ALandbouwBosbouwEnVisserij_92",
"BFNijverheidEnEnergie_93",
"GIHandelEnHoreca_94",
"HJVervoerInformatieEnCommunicatie_95",
"KLFinancieleDienstenOnroerendGoed_96",
"MNZakelijkeDienstverlening_97",
"RUCultuurRecreatieOverigeDiensten_98")En alleen op gemeente niveau, niet voor bv buurten of wijken en ‘versimpeling’ van de namen van de variabelen.
data_gemeentes <- data_all %>%
filter(str_detect(SoortRegio_2, "Gemeente")) %>%
select(all_of(mycols))
data_gemeentes <- data_gemeentes %>%
rename_with(str_replace, pattern = "_\\d+$", replacement = "")
names(data_gemeentes)## [1] "Gemeentenaam" "MateVanStedelijkheid"
## [3] "BedrijfsvestigingenTotaal" "ALandbouwBosbouwEnVisserij"
## [5] "BFNijverheidEnEnergie" "GIHandelEnHoreca"
## [7] "HJVervoerInformatieEnCommunicatie" "KLFinancieleDienstenOnroerendGoed"
## [9] "MNZakelijkeDienstverlening" "RUCultuurRecreatieOverigeDiensten"Ik bewerk de data om deze geschikt te maken voor de analyse in gedachte, o.a. type bedrijven als percentage van het totaal aantal bedrijven en mate van stedelijkheid als factor.
frac <- function(deel, totaal) {
deel/totaal*100
}
data_gemeentes_analyse <- data_gemeentes %>%
as_tibble() %>%
dplyr::mutate(ALandbouwBosbouwEnVisserijF = frac(ALandbouwBosbouwEnVisserij, BedrijfsvestigingenTotaal),
BFNijverheidEnEnergieF = frac(BFNijverheidEnEnergie, BedrijfsvestigingenTotaal),
GIHandelEnHorecaF = frac(GIHandelEnHoreca, BedrijfsvestigingenTotaal),
HJVervoerInformatieEnCommunicatieF = frac(HJVervoerInformatieEnCommunicatie, BedrijfsvestigingenTotaal),
KLFinancieleDienstenOnroerendGoedF = frac(KLFinancieleDienstenOnroerendGoed, BedrijfsvestigingenTotaal),
MNZakelijkeDienstverleningF = frac(MNZakelijkeDienstverlening, BedrijfsvestigingenTotaal),
RUCultuurRecreatieOverigeDienstenF = frac(RUCultuurRecreatieOverigeDiensten,BedrijfsvestigingenTotaal)
) %>%
mutate(MateVanStedelijkheid = as_factor(MateVanStedelijkheid))Mate van stedelijkheid a.d.h.v. percentage landbouw
Om een idee te krijgen van bv het percentage landbouw, bosbouw en visserij verdeeld over de gemeentes:
qplot(data_gemeentes_analyse$ALandbouwBosbouwEnVisserijF, geom = "histogram", bins=30)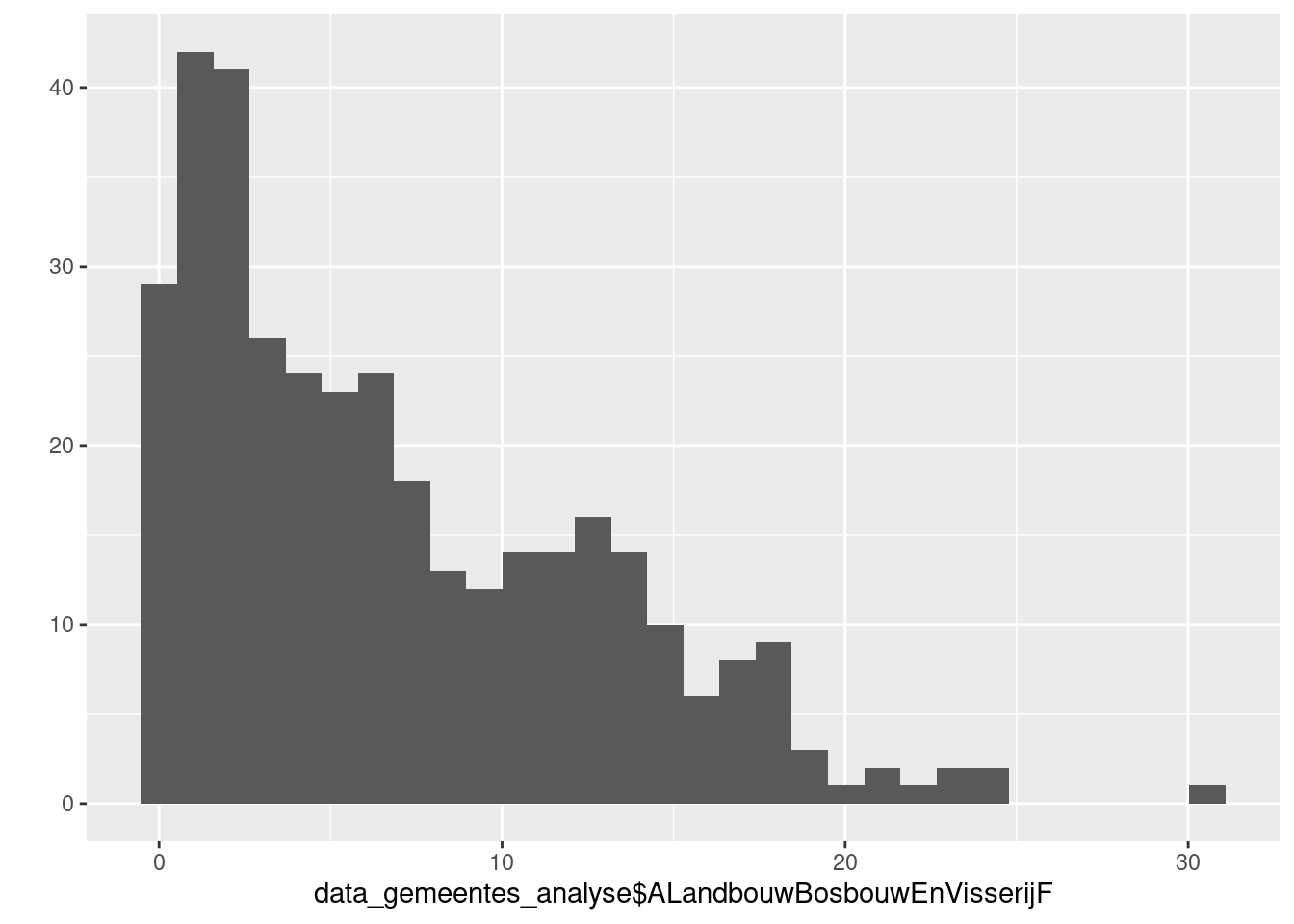
landbouwtree <- ctree(MateVanStedelijkheid ~ ALandbouwBosbouwEnVisserijF, data = data_gemeentes_analyse)
plot(landbouwtree,
main="Mate van stedelijkheid a.d.h.v. het % bedrijven landbouw, bosbouw en visserij")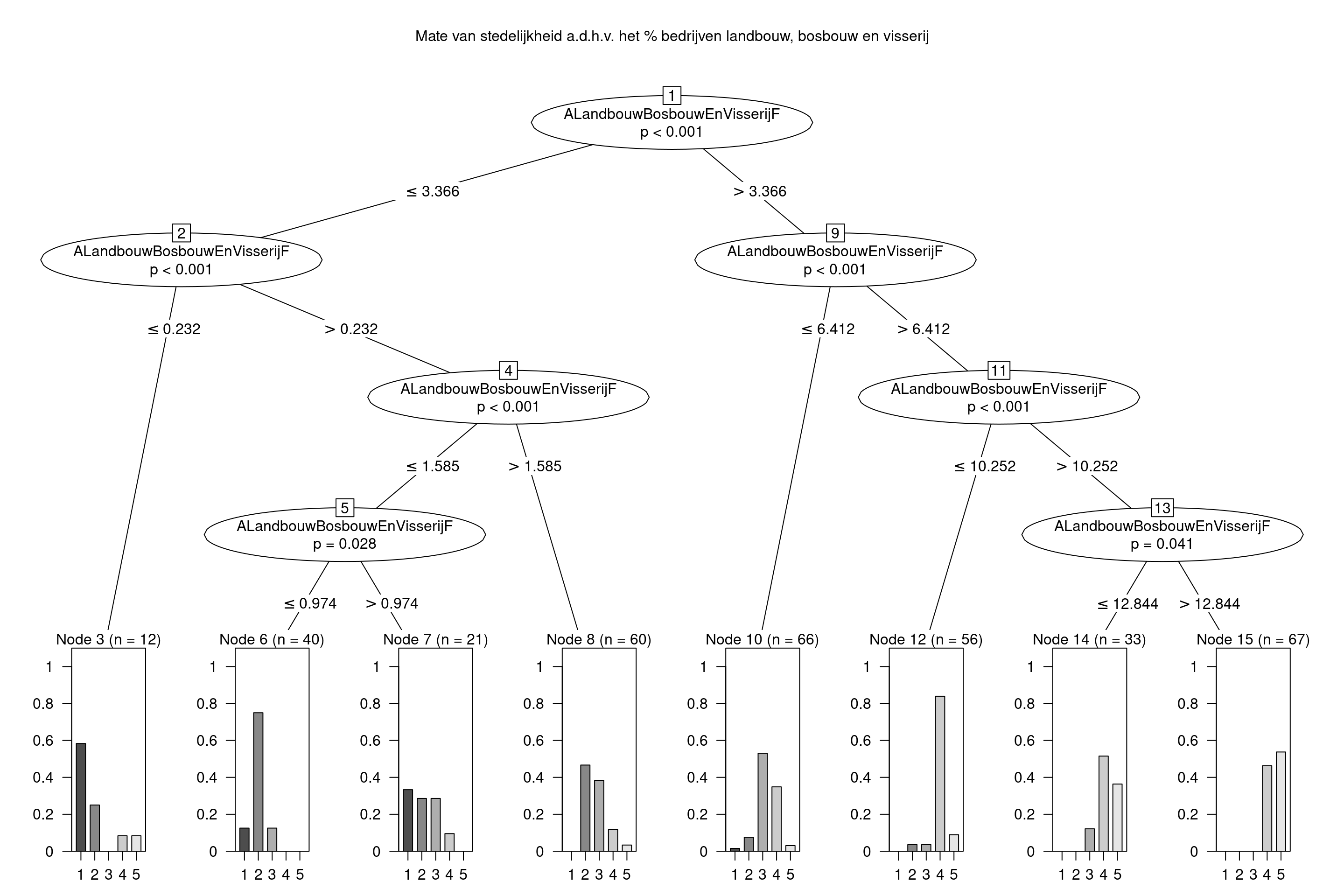
voorspel_stedelijkheid <- function(ptree, data, gemeente) {
gemeente_sample <- data %>%
filter(stringr::str_detect(Gemeentenaam, gemeente)) %>%
select(ALandbouwBosbouwEnVisserijF)
pred <- -1
if (nrow(gemeente_sample > 0)) {
pred <- Predict(ptree, as.list(gemeente_sample))
} else {
print(paste("Geen data voor", gemeente))
}
pred
}
voorspel_stedelijkheid_ok <- function(ptree, data, gemeente) {
gemeente_sample <- data %>% filter(stringr::str_detect(Gemeentenaam, gemeente))
pred <- voorspel_stedelijkheid(ptree, data, gemeente)
pred == gemeente_sample$MateVanStedelijkheid[1]
}
voorspel_stedelijkheid_ok(landbouwtree, data_gemeentes_analyse, "Oss")## [1] TRUEvoorspel_stedelijkheid_ok(landbouwtree, data_gemeentes_analyse, "Waalwijk")## [1] FALSEvoorspel_stedelijkheid_ok(landbouwtree, data_gemeentes_analyse, "Eindhoven")## [1] TRUEEen overzicht maken van de voorspellingen t.o.v. echte waarde:
voorspelling_ok <- map(data_gemeentes_analyse$Gemeentenaam,
function(x) {
as.integer(
voorspel_stedelijkheid_ok(landbouwtree,
data_gemeentes_analyse,
x)) }) %>% flatten_int()## [1] "Geen data voor Bergen (L.) "
## [1] "Geen data voor Bergen (NH.) "Hoe vaak is deze voorspelling goed?
barplot(table(voorspelling_ok), names.arg = c("fout", "goed"))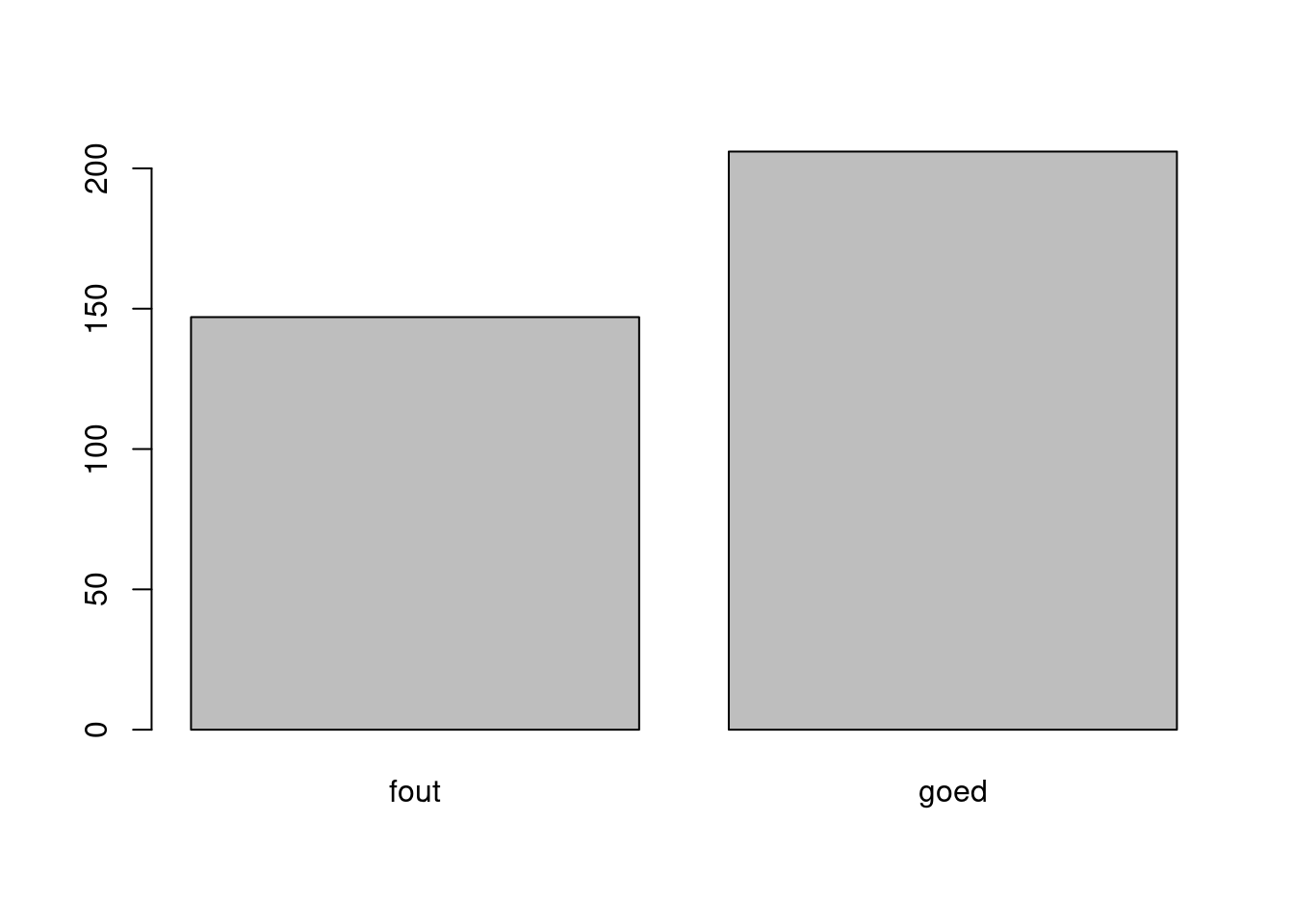 Is niet meteen indrukwekkend. Om het effect te zien van het gebruik van de de classificatie tree hieronder het verhaal als er random ‘voorspeld’ zou zijn.
Is niet meteen indrukwekkend. Om het effect te zien van het gebruik van de de classificatie tree hieronder het verhaal als er random ‘voorspeld’ zou zijn.
voorspel_stedelijkheid_random <- function(ptree, data, gemeente) {
pred <- sample(1:5, 1)
}
voorspel_stedelijkheid_random_ok <- function(ptree, data, gemeente) {
gemeente_sample <- data %>% dplyr::filter(stringr::str_detect(Gemeentenaam, gemeente))
pred <- voorspel_stedelijkheid_random(ptree, data, gemeente)
pred == gemeente_sample$MateVanStedelijkheid[1]
}
voorspelling_random <- map(data_gemeentes_analyse$Gemeentenaam, function(x) {
as.integer(voorspel_stedelijkheid_random_ok(NULL, data_gemeentes_analyse, x)) }) %>%
flatten_int()
par(mfrow = c(1:2))
barplot(table(voorspelling_random), names.arg = c("fout", "goed"))
barplot(table(voorspelling_ok), names.arg = c("fout", "goed"))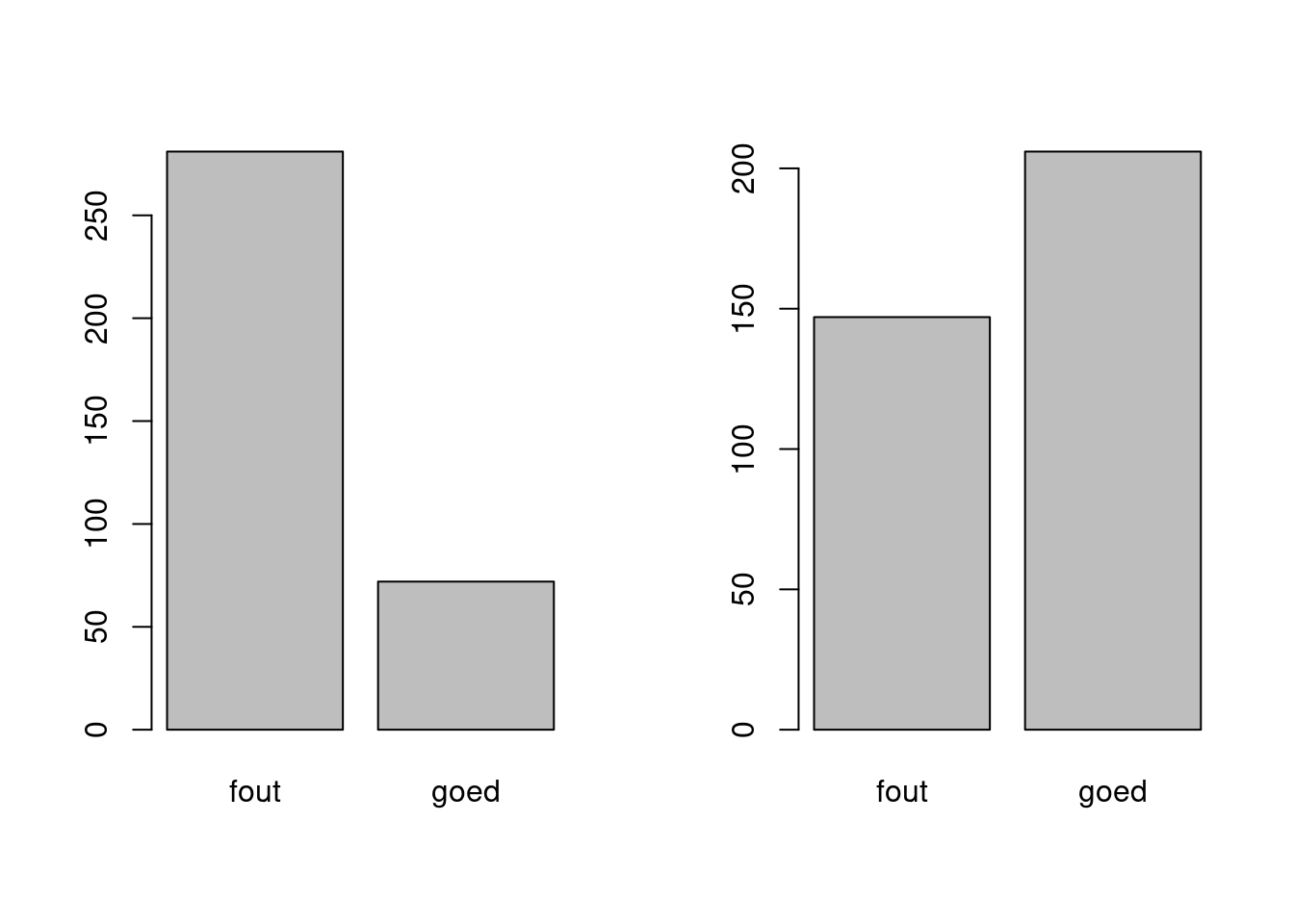
Mate van stedelijkheid a.d.h.v. percentage type bedrijven
partybedrijven <- ctree(MateVanStedelijkheid ~ .,
data = data_gemeentes_analyse %>% select(-Gemeentenaam))
plot(partybedrijven,
main="Mate van stedelijkheid a.d.h.v. % verschillende types bedrijven")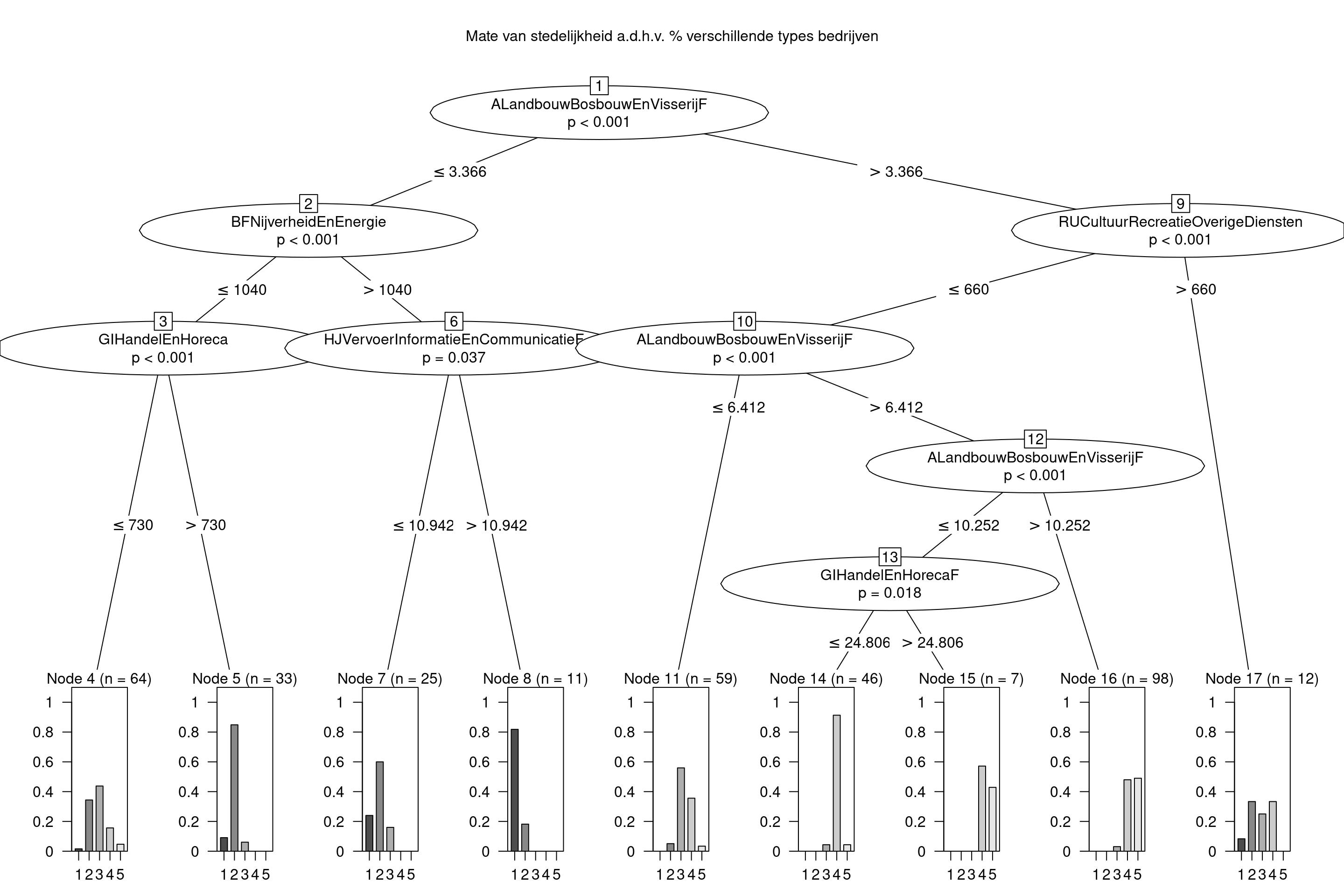
voorspel_stedelijkheid2 <- function(ptree, data, gemeente) {
gemeente_sample <- data %>% filter(stringr::str_detect(Gemeentenaam, gemeente)) %>%
select(-Gemeentenaam, -MateVanStedelijkheid)
pred <- -1
if (nrow(gemeente_sample > 0)) {
pred <- Predict(ptree, as.list(gemeente_sample))
} else {
print(paste("Geen data voor", gemeente))
}
pred
}
voorspel_stedelijkheid_ok2 <- function(ptree, data, gemeente) {
gemeente_sample <- data %>%
dplyr::filter(stringr::str_detect(Gemeentenaam, gemeente))
pred <- voorspel_stedelijkheid2(ptree, data, gemeente)
pred == gemeente_sample$MateVanStedelijkheid[1]
}voorspelling_ok2 <- map(data_gemeentes_analyse$Gemeentenaam, function(x) {
as.integer(voorspel_stedelijkheid_ok2(partybedrijven, data_gemeentes_analyse, x)) }) %>%
flatten_int()## [1] "Geen data voor Bergen (L.) "
## [1] "Geen data voor Bergen (NH.) "par(mfrow = c(1:2))
barplot(table(voorspelling_ok), names.arg = c("fout", "goed"))
barplot(table(voorspelling_ok2), names.arg = c("fout", "goed"))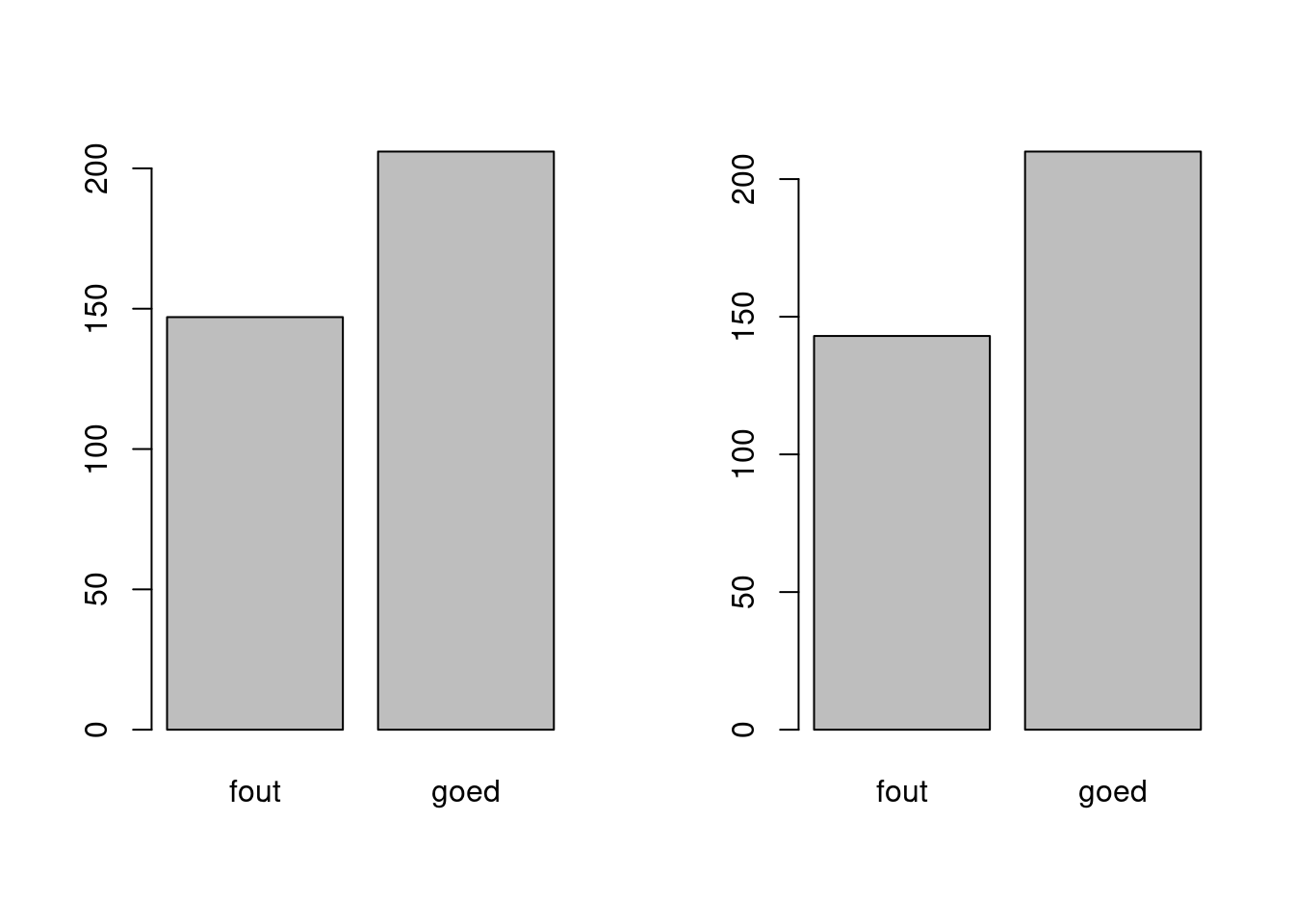
Dat is maar een kleine verbetering, maar genoeg voor hier en nu, qua analyse meer in de toekomst. Het ging vooral om snel wat te laten zien m.b.t. cbsodataR.
Eric van Esch
Data Engineer/ Data Scientist / Application Developer
Mijn interesse ligt bij het ontwikkelen van kwalitatieve en kwantitatieve modellen en deze implementeren in data-gedreven beslissing-ondersteunende applicaties.